Искусственный интеллект превращает размытые снимки в четкие фото
Сидя в своей квартире в Лос-Анджелесе 2019 года, детектив Рик Декарт сканирует фотокарточку, задает координаты компьютеру, а тот послушно увеличивает едва различимое на снимке изображение потенциальной жертвы.
Многие помнят эту сцену из культового научно-фантастического фильма Ридли Скотта "Бегущий по лезвию": мутное, едва различимое пятно на фото превращается в портрет человека с невероятной, даже пугающей реалистичностью.
До сих пор получить подобное крупное четкое изображение лица из маленькой размытой фотографии, как сделал Декарт, казалось невозможным.
Однако исследователям из Университета Дьюка в Северной Каролине (США), кажется, удалось приблизиться к воссозданию сцены из знаменитого фильма.
Ученые разработали модель искусственного интеллекта (AI), способную превратить пикселированное изображение лица низкого качества в портрет с ошеломляющей четкостью и проработкой деталей.

В фильме "Бегущий по лезвию" тусклое пятно, едва различимое в отражении в зеркале, превращается в четкий портрет лежащей на диване женщины
"Никогда еще не удавалось воссоздать изображения сверхвысокого разрешения с таким количеством мелких деталей", — рассказала Би-би-си соавтор разработки Синтия Рудин.
Алгоритм способен, по сути, "додумывать" и дорисовывать мелкие черты и детали лица, мимические морщины и ресницы, которые отсутствовали на пикселированном изображении.
Эксперты отмечают, что у этой технологии огромный потенциал в самых разных областях, включая сферу искусства, журналистику, медицину или астрономию.
Но у него есть недостаток: изображения получаются чрезвычайно реалистичными, но при этом нереальными: с лицом, изображенным на оригинальном фото, они имеют мало общего.
Полицейским и спецслужбам она не поможет: из пикселированного изображения восстановить портрет, соответствующий оригиналу, невозможно в принципе, считают исследователи.
Корреспондент Би-би-си протестировала на себе алгоритм AI и убедилась в том, что конечная фотография существенно отличается от оригинала.
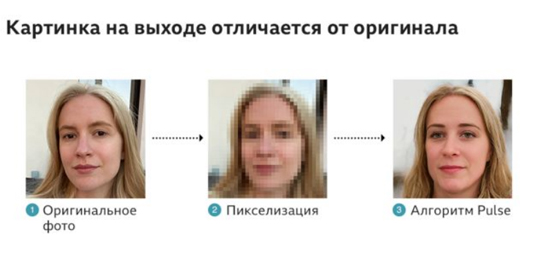
Как работает новый метод и чем отличается от предыдущих?
При традиционном подходе к улучшению качества изображения компьютер подбирает, а по сути, угадывает недостающие в низкокачественной фотографии пиксели на основании тех фотографий в высоком разрешении, которые были показаны ему ранее.
"Традиционные методы берут набор данных изображений в большом разрешении, сжимают их и учат нейронную сеть, чтобы итоговые изображения были попиксельно схожи с оригиналом из массива данных", — объясняет разработчик в сфере компьютерного зрения Андрей Володин.
Но у этого метода есть недостаток. К текстурным участкам изображения, таким как волосы или кожа лица, трудно подобрать подходящие пиксели. Портреты на выходе выглядят нечетко и размыто.
"Чтобы выполнить задачу, нейронная сеть пытается усреднить все возможные картинки, которые могут получиться, и в результате мы получаем нечеткое изображение", — говорит эксперт.
Исследователи из Университета Дьюка пошли по принципиально другому пути: саму задачу, которая ставится перед машиной, они сформулировали по-другому.
Эволюция нейросетей позволила кардинально изменить подход к улучшению качества изображений. Новые, ставшие популярными математические модели не просто превращают одну картинку в другую, а сами генерируют, создают изображения.
Одна из таких генеративных сетей, StyleGAN2. Вместо того, чтобы создавать из маленькой картинки большую, похожую на нее, как это делали в предыдущих методах, новая система заходит с противоположной стороны — она изначально формирует изображение высокого качества на основе огромного массива генеративной сети (миллионы снимков для анализа берутся, в частности, с фотосайта Flickr) и ухудшает его, производя низкокачественную копию.

Полученное изображение сличается с заданным снимком, и процесс повторяется до тех пор, пока все пиксели уменьшенной копии сгенерированного AI портрета не будут соответствовать заданному изображению.
Такой подход решает проблему детализации, так как картинка, которую нужно получить на выходе, уже изначально содержит все мелкие черты.
Поскольку Модель StyleGAN2 чаще всего учится на массиве данных ограниченного характера — в основном на лицах людей, экстраполировать ее на изображения другого содержания на этом этапе вряд ли получится.
"Если мы, например, загрузим маленькую картинку космического корабля, то ничего хорошего на выходе не получим — у системы нет образцов для формирования подходящего изображения, — объясняет Володин. — Если вы захотите проделать то же самое с фотографией ландшафта или какого-то здания, вам понадобится модель, которая способна генерировать ландшафты и здания. Это вопрос недостатка данных".
"Не факт, что вы узнаете себя"
Эксперты соглашаются с тем, что результаты исследования можно назвать достижением в сфере машинного обучения, но о научном прорыве речи не идет.
"Если у кого-то есть иллюзии, что это открытие в ближайшее время приведет нас к сценарию из фильма про ФБР, когда полицейские успешно увеличивают запикселированное изображение преступника с камеры наружного наблюдения, то этого не случится", — говорит Андрей Володин.
На этом же настаивают и авторы разработки.
"Недавно я получила имейл от полицейского, — говорит Синтия. — Он написал, что его работа — пикселировать лица с камер видеонаблюдения, которые необходимо скрыть, и что мы подрываем его дело, работаем против него. Как раз наоборот, ответила я. Мы показываем, почему его работа важна".

"Каждой маленькой картинке могут соответствовать сотни вариантов изображений высокого качества, поэтому восстановить точное изображение лица из пикселированного невозможно", — подытоживает Синтия.
Итоговое изображение может получиться чрезвычайно четким, но не факт, что на выходе получится тот самый человек, что был запечатлен на оригинальном снимке.
Так, если вы возьмете свою детскую нечеткую фотографию и загрузите ее в систему, на выходе нейросеть выдаст снимок человека с тем же цветом кожи, разрезом глаз, как у вас, и похожими чертами лица, но это будете не вы.
"Представьте, что вы уменьшаете картинку, на которой был некий текст. До тех пор, пока пиксели отражают хоть какие-то очертания букв, модель может справиться. Но если мы уменьшим изображение настолько, что каждая буква превратится в пиксель, крохотный квадратик, то мы уже ничего не сможем сделать. Каждый такой квадратик может быть похож на любую букву из алфавита любого языка мира".
Тогда кому и зачем это нужно?
От медицины до астрономии?
Если нейросеть не способна восстановить оригинальный портрет лица, то может делать прямо противоположное: видоизменять лица людей, где это требуется.
Метод пригодится полицейским, которым нужно скрыть лица информаторов или ключевых свидетелей, журналистам, не желающим раскрывать портреты анонимных или уязвимых собеседников. До сих пор лица таких людей приходилось размывать в фоторедакторе, при этом существовали опасения, что этот процесс может быть обратимым.
Система PULSE изящно решает эту задачу: вы видите четкий портрет, но узнать в нем реального человека невозможно.
Семейство этих методов может совершить прорыв в сфере медиа и кино, где достоверность образа не так важна.
Например, можно будет прогонять через модель старые фильмы, архивные кадры кинохроники или мультфильмы, получая на выходе формат сверхвысокого разрешения — 4-8 тысяч пикселей, что будет эстетически красиво, даже если герои не на 100% будут выглядеть, как в оригинале.
"Если мы возьмем за основу не крохотное изображение 16×16, как в этом исследовании, а разрешение с камеры в метро 254х254 и прогоним его через алгоритм, на выходе может получиться что-то правдоподобное", — отмечает Володин.
Генеративная сеть может взять за основу фотографии низкого разрешения почти любого содержания и превратить их в четкие изображения, утверждают исследователи.

До сих пор получить подобное крупное четкое изображение лица из маленькой размытой фотографии, как сделал Декарт, казалось невозможным.
Сфера применения технологии потенциально может быть чрезвычайно широкой — от компьютерных изображений в медицине или астрономии до спутниковых снимков земных ландшафтов.
"Это возможно благодаря ограниченному числу возможных вариантов изображений. Почти все фотографии из астрономии — "черный фон и белые точки", или снимки с МРТ в медицине. В таких случаях нейросеть может быстро выучить эти вещи", — говорит Андрей Володин.
Вопрос только в доменах данных различных объектов, которые сейчас ограничены.
"Но если же мы говорим о бесконечном пространстве изображений, куда входят все фотографии всех лиц на Земле, метод авторов точно неприменим", — подводит итог ученый.
Если какая-либо информация отсутствует в исходном изображении — например, совершенно неразличимый номер на фотографии машины или маленькое пятнышко на отражении в зеркале, как в "Бегущем по лезвию", из которого вырастают все последующие события фильма, то восстановить это изображение до степени полного сходства, скорее всего, окажется невозможно в принципе.
Так что сюжет знаменитой кинокартины, пожалуй, останется хоть и научной, но все же фантастикой. По крайней мере, пока искусственный разум не совершит нового эволюционного скачка.
Источник: bbc.com
{kind=link}